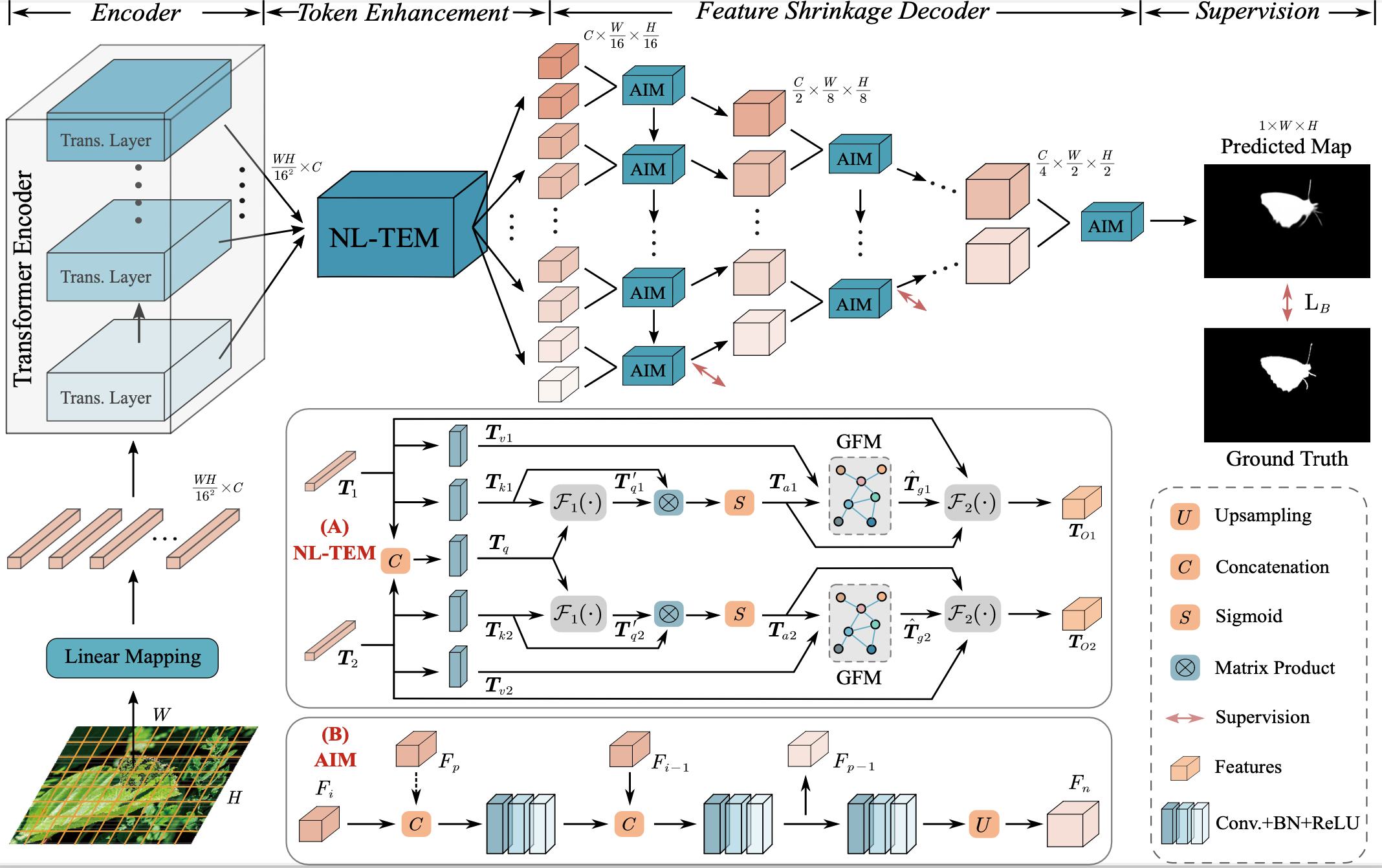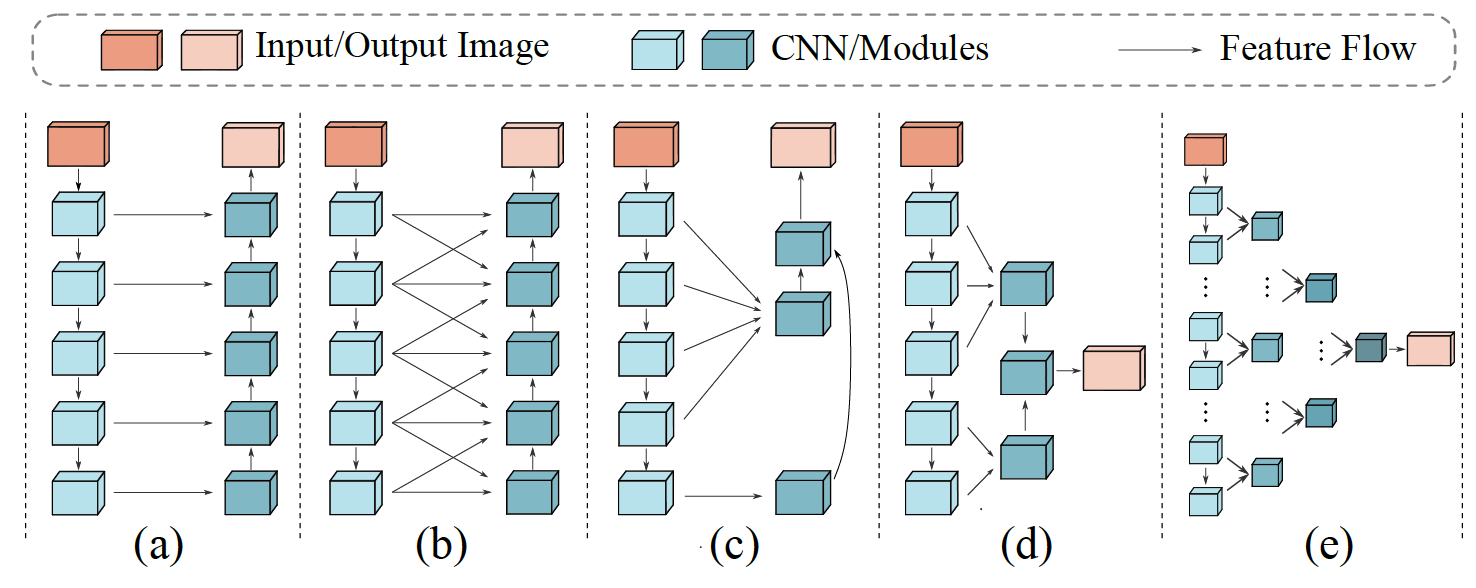
Left: Visual comparison of COD in different challenging scenarios. Right: Different types of decoding structures
for object segmentation: (a) U-shaped decoding structure, (b) dense integration strategy, (c) feedback
refinement strategy, (d) separate decoding of low-level and high-level features, and (e) our decoding structure.